

Building Recommers with Explicit Feedback Using Tensorflow: A Supervised ML, Regression Approach




Photo by Danist Soh on Unsplash
Introduction
In today's world, there is so much content to enjoy. Because of this, choosing what to watch, listen to, or even read is harder (the paradox of choice). Simply go to Netflix and choose a movie to watch among so many options, see how easy that is.
For this among other reasons, a lot of companies are committing resources to building and integrating recommenders into their products, for the sole aim of helping users choose.
However, many curious users and newbie data scientists, do not know what recommenders talk-less of how they work.
Look no further, in this article, I will demystify recommendation algorithms by explaining what they are, and how they work. I will also work through a use case in which, I will be building a simple recommendation algorithm
Let's begin!
What Is A Recommender?

A recommender or recommendation algorithm is a type of algorithm that increases the visibility of items a user is known to be interested in. These suggestions are often termed personalized because they rely on behavioral information of the user (implicit), or opinions left by the user about some item they interacted with previously.
In times when we have unlimited options on streaming platforms and e-commerce websites, recommenders make it easy for us to find things we like. Imagine a friend of yours recently introduced you to the song Bohemian Rhapsody by Queen and on first listen (on YouTube Music) you were hooked, and wish to listen to similar songs, or other tracks by the band. You don't need to search or stress much, a recommender will surely bring to your home screen similar songs sung by Queen, among other things.
Types of Recommenders
Broadly speaking there are three types or categories of recommenders. They are:
Content-Based Recommendation System
Collaborative Filtering Recommendation System
Hybrid Recommendation System
Content-Based Recommendation System provides suggestions based on the content the user has interacted with. Such algorithms recommend items similar to past interactions.
They work by:
Creating numerical representations of the items a user(s) has interacted with previously, and also does the same for all items in the database
Makes use of some mathematical technique (a suitable one is Cosine Similarities) to score how similar or dissimilar items in the database are to users' interactions. These scores are usually between 1 (most similar) and -1 (most dissimilar)
The items with the highest scores are the output of the algorithm
As practical as this sounds, it is not without disadvantages. A prominent one is that the user must have a history of interactions before a suggestion is possible, making it problematic in situations where the user has no interaction history.
Collaborative Filtering Recommendation System works a bit differently from its counterpart.
This category of recommenders provides suggestions based on the similarity between users and/ or items. It is premised on the assumption that there are similarities in characteristics and behaviors between users, and those similar are more likely to be interested in the same thing.
Let's assume that Users A and B like the same genre of music. Interestingly, they are within the same age bracket, work white-collar jobs, and live only a few miles from each other. We can say that these users are similar and we can then recommend songs on their playlists to each other.
This way of providing suggestions gives Collaborative Filtering techniques an edge over content-based recommendation algorithms. They can provide recommendations for a new user who has no interaction history.
Some prominent approaches to collaborative filtering techniques for recommendations include matrix factorization, where the objective is to learn the behaviors of users, in their interaction items
Hybrid Recommendation Systems as the name suggests, involves a combination of algorithms belonging to the two previous categories of recommenders. The two categories of algorithms are combined in a way that leverages their advantages. They can be combined sequentially, parallelly, or otherwise.
Feedback: Explicit Feedback vs. Implicit Feedback
Feedback to recommendation algorithms can be likened to oil (lubricant) to combustion engines, they are important for recommenders to continue working as expected. Feedback in this context refers to communication from the user to a recommendation system, which details how well the service was enjoyed by the user.
User feedback can be categorized as follows:
explicit feedback
implicit feedback
Explicit feedback is explicitly provided by the user and indicates how much the user liked or disliked a certain service or product. Prominent examples include likes (👍 ) or dislikes (👎 ) indicated by a Netflix subscriber after they have watched a movie, a rating (from 1 to 5) indicating how useful a particular product was for a user after a purchase from Amazon, etc
Recommenders make use of this type of feedback and provide similar items to those the user rated highly or liked. At the same time, they reduce the visibility of items the user disliked or was dissatisfied with.
The problem with explicit feedback is that it is rarely provided by the user. For example, several videos on YouTube have a high number of views, running into millions in some cases, but have just a few likes. This is a major setback that can be encountered when building recommenders based on explicit opinions.
Implicit Feedback is quite different. It refers to behaviors, actions, or inactions of a user concerning a particular service or product.
For example, If you are looking for a robot vacuum cleaner and you click on a listing on Amazon and even go ahead to purchase it, this implies that you are interested in that sort of appliance. Amazon's recommenders can therefore suggest similar devices to you or take it a step further and make use of association-rule learning to recommend products that can be used along with the robot vacuum cleaner.
This type of feedback is usually preferred when building recommenders as they are abundant and not dependent on the user to provide.
However, this article will work mostly with explicit feedback as you will see in the next section
Building a Recommendation Algorithm

Overview of the Data
The data used to build this algorithm is the Movies & Ratings For Recommendation, you can find this on Kaggle.
At a simple glance, we see that:
Users are represented with IDs in the form of integers ranging from 1 to 610. Also included in the dataset are movie IDs, titles, movie genres as well as the ratings given to these movies.
The data is clean, with no missing or duplicate rows, and is organized into two files namely: movies.csv and ratings.csv
below are previews of the datasets:
movies_df:
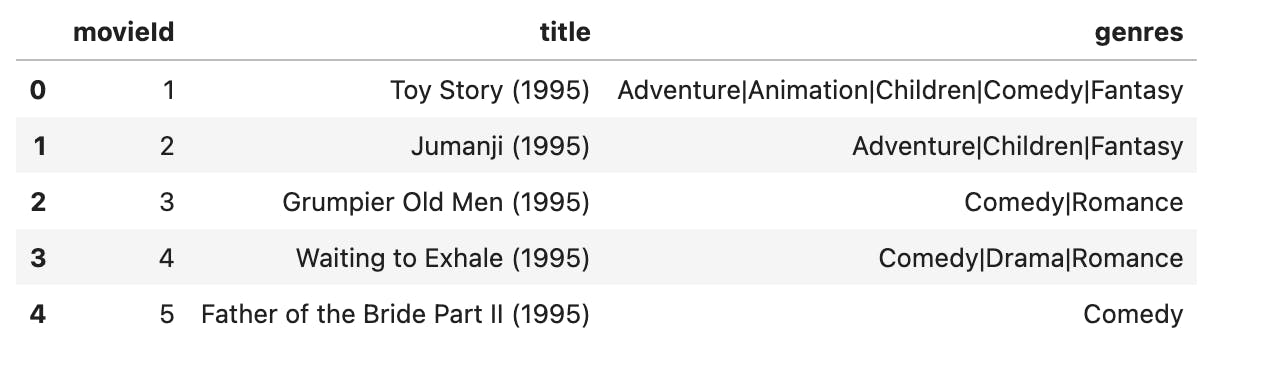
ratings_df:

The lowest and highest ratings are 0.5 and 5 respectively, where 0.5 indicates a dislike or dissatisfaction with the movie watched, and 5 means the opposite. With regards to distribution, 4.0 is the most prevalent rating, reaching about 30,000 in frequency. It is closely followed by 3.0 which stands at 20000 also in terms of frequency. Below is a visualization showing how frequent each rating is:

What Can User Ratings Tell Us About Their Preferences?

Each user has a preference for certain genres of movies and this is indicated by how high they rate them. The contrary is also true, some genres are disliked by some users. Take user 1 for example (pay attention to the first row in the image above), they rate action movies, musicals, animation, and comedies among others, 5. Whereas, horror, romance, and western movies are rated less than 5. We can see this pattern of behavior across numerous users.
From an ML modeling perspective, it also means that movie genres are a good feature for the model to consider when estimating the ratings a user might give to a particular movie (more on this in the next subsection).
Assumption, Approach, and Metrics
Guiding Assumption
The solution is guided by the following assumption:
If we can estimate the rating a user will give a certain movie, given the user's ID, the movie title, and its corresponding genre(s), then we can suggest movies to users based on estimated ratings, where the predicted ratings are >= 4.0.
And so, efforts are directed towards building a Supervised ML, Regression Model capable of correctly estimating the ratings a user will give to a particular movie
Why Regression?
It is easy to confuse the ratings for discrete values since they are within a certain range. Also considering that continuous values can be as low as 0 and as high as infinity, it isn't strange to interpret them as discrete values.
However, continuous values measure variables, (how well a user likes or dislikes a movie) whereas discrete values represent classifications. This implies that continuous values can be whole integers (1, 2) or float values (0.57, 0.98) while discrete values can only be integer values.
Therefore, the choice for a regression model is solidly built on these points:
The ratings are float values
They measure how well a user likes or dislikes a movie.
Technical Metrics
The Mean Absolute Error (MAE) is adopted as the metric and loss function for the model. As a regression evaluation metric, the MAE indicates how wrong or far off a prediction is from an actual value. The lower the MAE score is, the better the model. The higher the score, the worse the model is.
Mathematically, we can define the Mean Absolute Error as the sum of the absolute errors divided by the total number of observations.
$$\begin{align*} \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} \left| y_i - \hat{y}_i \right|\\ \\ where: \hspace{6cm}\\ n\hspace{0.2cm}=\hspace{0.2cm}number\hspace{0.2cm}of\hspace{0.2cm}samples\\ y_i\hspace{0.2cm}=\hspace{0.2cm}actual\hspace{0.2cm}value\hspace{2cm}\\ \hat{y_i}\hspace{0.2cm}=\hspace{0.2cm}predicted\hspace{0.2cm}value\hspace{1.1cm}\\ \end{align*}$$
Data Processing and Transformation
movie titles
Remember that our regression model will consider a user ID, movie title, and associated genres before estimating a rating. These features cannot be used in their existing form. For one, the movie title is a string and Deep Learning Models do not work well with strings, creating a necessity for embeddings.
Embeddings for the movie titles are therefore generated with a StringLookup() and a Embedding() layer. Firstly, a vocabulary is built from the existing movie titles, and then the movie embedding model is constructed through Tensorflow's Sequential API.
The embeddings are subsequently generated and stored in a NumPy array of shape 100836 rows and 64 columns
movie_titles_vocabulary = tf.keras.layers.StringLookup(
mask_token = None
)
movie_titles_vocabulary.adapt(prep_df['clean_title'].values)
movie_model = tf.keras.models.Sequential(
[
movie_titles_vocabulary,
tf.keras.layers.Embedding(
movie_titles_vocabulary.vocabulary_size(),
64
)
]
)
X_movie_embs = movie_model(prep_df['clean_title']).numpy()
user ID
The user IDs on the other hand are already integers. While the model has no issues working with it, they are encoded with embeddings as well with the same method detailed above. Rather than a StringLookup() layer, an IntegerLookup() layer is used since the values in this case are integers.
user_id_vocabulary = tf.keras.layers.IntegerLookup(mask_token = None)
user_id_vocabulary.adapt(prep_df['userId'].values)
user_model = tf.keras.Sequential(
[
user_id_vocabulary,
tf.keras.layers.Embedding(
user_id_vocabulary.vocabulary_size(),
64
)
]
)
X_userId_embs = user_model(prep_df['userId']).numpy()
movie genres
The movie genres are however encoded with binary values, where 1 indicates a genre value is present and 0 means otherwise.
Since there are 20 distinct movie genres in the dataset, the array encoding the movie genres for each userId will have a shape of 1 row by 20 columns. This is to ensure there are no shape-related errors during model training.
Here is the Python function used to achieve this
def encode_movie_genres(genres):
unique_genres = list(np.unique(
'|'.join(prep_df['genres'].unique().tolist()
).split('|')))
result = [
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
]
for genre, index in zip(unique_genres, range(len(result))):
if genre in genres:
result[index] = 1
else:
result[index] = 0
return result
Model Development

Model Architecture
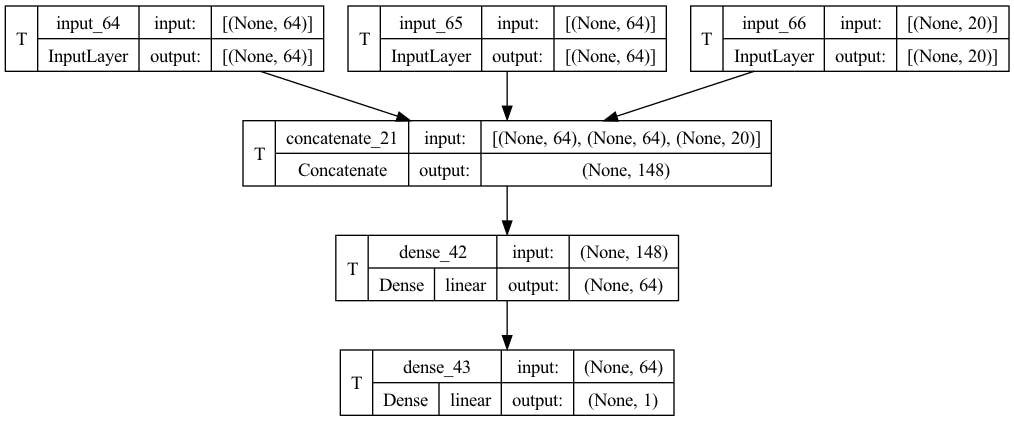
The model is expected to take in three different inputs and these are user IDs, movie titles, and genres represented in their respective embeddings. To cater to this, Tensorflow's functional API is used to create a multi-input model. The first two inputs from the left are for the user ID and movie title embeddings and each of them has 64 input neurons (recall that these embeddings have 64 columns each). The third input layer takes in the encoded movie genres and has 20 input neurons.
The inputs are concatenated through a concatenation layer, which results in an output of 148 features. These features are fed into a single hidden layer made up of 64 inputs, after which the predicted rating is received.
A Training set is used to build the model, while a test set is used to assess the knowledge of the model.
Model Performance
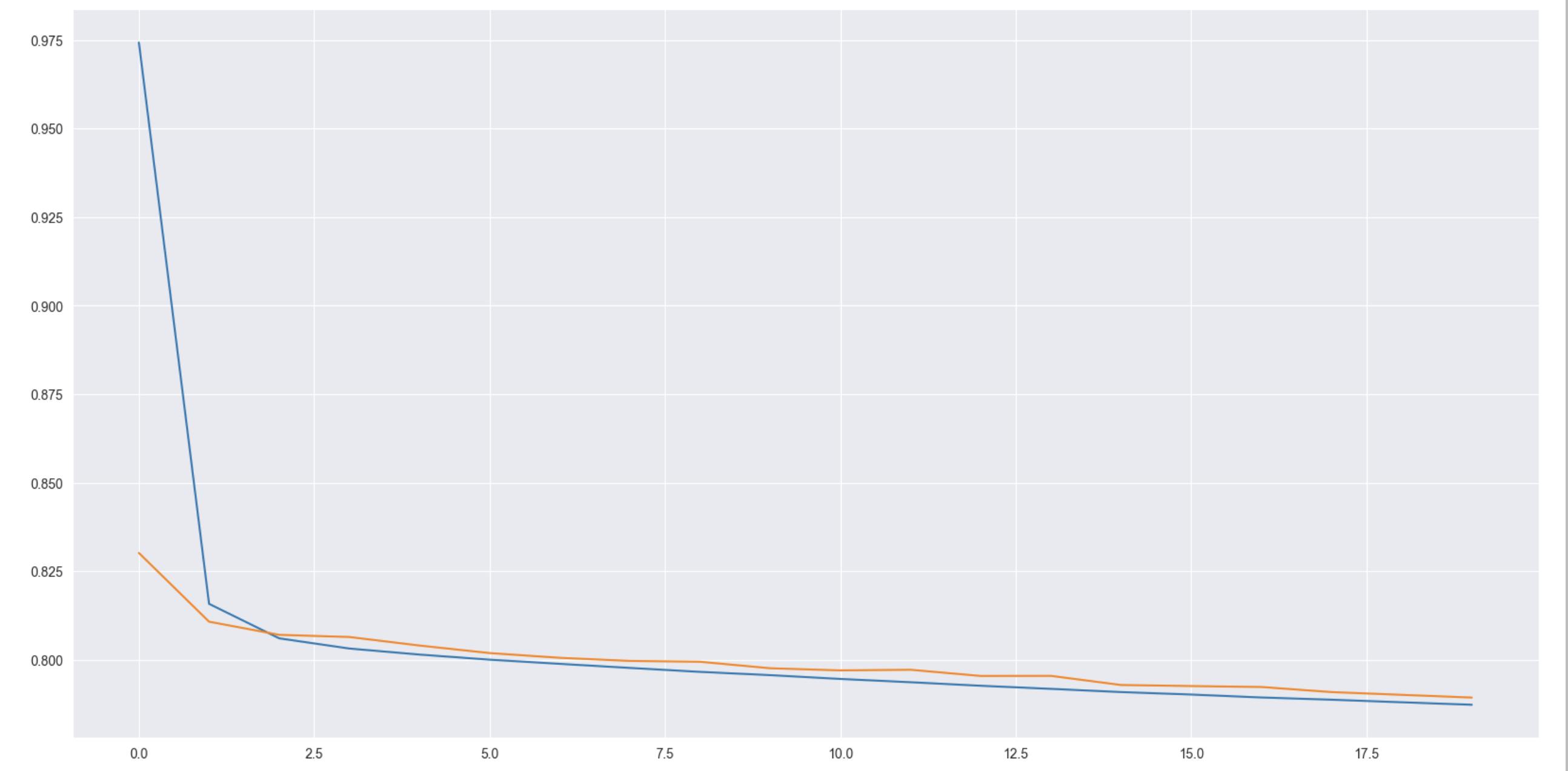
The model is trained for 20 epochs on batches of the dataset, each batch is made up of 128 instances of data. Initially, the training loss was quite high at almost 0.975, while that of the validation is low, indicating underfitting. However, as the model trains, it produces a decent performance on the validation set. At the 20th epoch, we see the model has a mean absolute error of around 0.780. This means that its predictions are 0.780 off from the actual ratings provided by the users.
A Simple Demonstration
def clean_titles(title):
title = title.split()
del title[-1]
title = ' '.join(title)
title = title.lower()
title = re.sub('[^a-z0-9]', ' ', title)
title = ' '.join([
word for word in title.split() if word not in stop_words
])
return title
def create_rec_sys_dataset(userId):
data = movies_df[['title', 'genres', 'movieId']].drop_duplicates()
data['clean_title'] = data['title'].apply(clean_titles)
data['userId'] = userId
return data
def compute_embeddings(data):
user_id_embeddings = user_model(data['userId']).numpy()
movie_embeddings = movie_model(data['clean_title']).numpy()
genre_embeddings = np.array(data['movieId'].map(
genres_movie_id_dict
).tolist())
return user_id_embeddings, movie_embeddings, genre_embeddings
def predict_ratings(user_embeddings, movie_embeddings, genre_embeddings):
prediction = np.round(rating_model.predict(
[user_embeddings, movie_embeddings, genre_embeddings]
), 1)
return prediction
def recommend_movies(userId):
data = create_rec_sys_dataset(userId)
user_id_embeddings, movie_embeddings, genre_embeddings = compute_embeddings(data = data)
prediction = predict_ratings(
user_id_embeddings,
movie_embeddings,
genre_embeddings
)
data['predicted_rating'] = prediction
return data['title'].loc[data['predicted_rating'] >= 4.5].tolist()
With the model and the code above, we can recommend movies for any user, by passing in the respective user ID into the recommend_movies() function. Recommending movies for user 1 for example, we get the following output:

Conclusion
Making it this far, it is most likely you now understand what recommenders are, how they work, and how to build one from scratch as a data scientist. If you are a non-technical person interested in this topic, it is also likely you have an overview of what recommenders are and how they work.
You can build upon this example, by making the model more complex or using a different approach together.
A hint: you can experiment with training embeddings for user IDs and movie titles, where the highly rated movies have embeddings closer to the respective user IDs and lower-rated ones have embeddings farther away.
Please leave a comment, if you have questions or observations you like to discuss. Also, take a look at my blog for other interesting articles.