

Enhance Backend Data Security with Standard Data Management Practices

I enjoy working on and building complex classification systems, writing how-to pieces to guide new bees in the data science field. In my free time I enjoy learning how to use new technologies and spending time with family
Oluwaseyi Emmanuel Ogunnowo,
Machine Learning Engineer, Terragon Ltd, Nigeria
Data has unarguably become the most prized resource of the 21st century. Tech Giants, multinational corporations, and businesses have identified ways of collecting data through a variety of channels. But in its raw form, data is messy, incomprehensible and of no use to anyone.
Think of it like a roughened-up piece of paper that contains information about stock prices of a particular company, you may not find helpful information until you straighten it out.
Once messy data has been cleaned out and processed, there is a need to sort it properly and efficiently. In this article, I will be going in-depth into data management, its modern components, best practices, the need for standardization as it relates to data security, and how this has changed over the years. This would help put into perspective the need to transition away from legacy practices and tools.
What is Data Management and why do we need it?
Data Management is a broad term that denotes processes related to collecting and organizing data from its raw form to storage and effective use. According to Oracle , It refers to the process of managing data in a secure, cost-effective, and efficient way, through a multi-layered process that involves ingesting, storing, organizing, and maintaining data.
These definitions are limited, without discussing the multi-layered process data management entails. Thus, we will be looking at these from the lens of best practices and standards. Here are the five major components of data management and the standard practices involved in them.
Data Architecture: This is the first and most important component in the data management process. Data architecture maps out data flows through an organization; from collection to analytics, while highlighting the technical and data requirements as it relates to the business objectives.
A data architectural framework specifies the sources/producers of the data needed, as well as the collection, and ingestion procedures. Also specified in the data blueprint are data transformation processes, storage requirements, and usage. Below is an image that explains the specifications of data architecture sequentially.
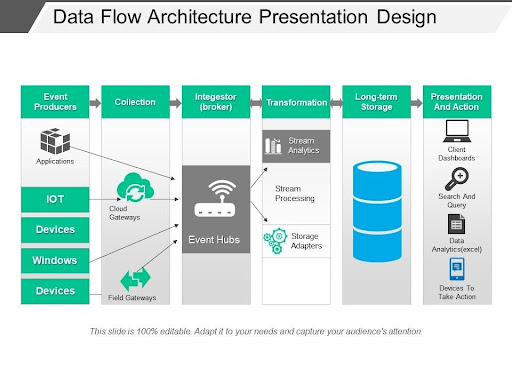 Source: https://www.slideteam.net/data-flow-architecture-presentation-design.html
Source: https://www.slideteam.net/data-flow-architecture-presentation-design.html
Data Collection and Ingestion: Building on the data architecture phase and its specifications, the next step is collating and ingesting the data. As seen in the sample data architecture flow above, we have the event producers, which in this case are data sources, this is where collation begins. Typical data sources include: Machine data sources (Internet of Things, devices, web or mobile applications, and network servers), Files data sources (log files, external data files, etc)
Next to data collection are the ingestion processes, also known as “the broker”. Data ingestion in some cases marks the starting point for what is known as the ETL processes (Extraction Transformation and Load). Here the data is aggregated, cleansed, and deduplicated to make it better organized.
Data Storage: Having clean data is not enough, it needs somewhere secure to stay, to be stored. At the same time, simply dumping all your gathered data into an Excel sheet or database is unacceptable as you risk data loss. This makes data storage an integral part of the data management process.
The manner and approach in which data is stored determine many things, including accessibility, ease of use, and even security. But data storage is also determined by the type of data that needs to be stored i.e With structured data, (typical table with fields (columns) and records (rows)) a relational database can be your storage choice using Structured Querying Language (SQL) as the tool to access your data. On the other hand, non-relational databases are a suitable choice for storing unstructured data (data not arranged according to a predefined schema).
However, the choice of where to store data should prioritize all practices, processes, and technologies to prevent unauthorized access to information assets and inappropriate use of them
Data Security and Protection: This is one of the most critical components of data management. And sadly, it is one of the most neglected. Stopping at data storage without preventing authorized usage is one of the many flaws that affect data security and best practices as a whole. Here are a few ways to ensure data security:
Encryption: This takes several forms, two of which are encryption-in-transit and encryption-at-rest. As the name implies, it ensures that data is protected even while the transformation processes (ETL) are ongoing and as well as when it gets to storage.
Tokenization: Wikipedia) explains this as the process of substituting a sensitive data element with a non-sensitive equivalent, referred to as a token, that has no extrinsic or exploitable meaning or value. The token is a reference that maps back to the sensitive data through a tokenization system. Such tokens are only retrievable by this system.
Replacing live data with tokens is intended to minimize exposure of sensitive data to applications, stores, people, and processes, reducing the risk of compromise, accidental exposure, and unauthorized access to sensitive data.Access control: For regulating who has access to the data. Since this in most cases requires manual effort, access and passwords can be easily breached, it shouldn’t be regarded as the safest option.
A relevant data security plan must consider gathering only the required data, keeping it safe, and erasing information properly, once it is no longer needed. It’s necessary to retain data intelligently and avoid redundant archived copies. These might involve putting in place some privacy and internal policies that guide how data is secured and/ or disposed using the methods highlighted above.
Data Analytics and Insights Extraction: This is the last part of the data management chain. Once the data has undergone all other processes of data management, it is now time to extract meaningful insights from it using a variety of techniques. These include Exploratory Data Analysis i.e performing investigations on data to identify hidden patterns, spot anomalies, model iteration to predict outcomes, and cluster similar data points as the case may be.
The EDA process is aptly represented by statistical and graphical representations. Here is a pictorial representation of the EDA process.
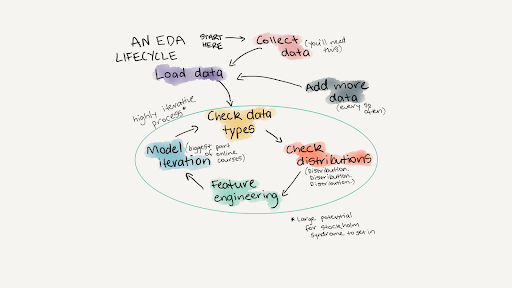 Source: https://www.mrdbourke.com/a-gentle-introduction-to-exploratory-data-analysis/
Source: https://www.mrdbourke.com/a-gentle-introduction-to-exploratory-data-analysis/
Why the need to standardize data management and security practices
As earlier stated, data security has evolved over the years and so has the way it is managed. Before now, much heed wasn't taken to how it is stored as long as it was available to use and generate insights. This was permissible because technology had not evolved to allow for remote storage options that cloud services now offer.
Also, recent software and framework releases have emphasized the need for standardization as some legacy processes have become obsolete. Let’s see a few use-cases:
- Data Governance
This lays out policies that guide data usage. In doing so, it helps avoid errors, blocks misuse of sensitive data, and aligns corporations with data-related legislation such as the EU’s General Data Protection Regulation (GDPR).
Before now data governance only covered processes of cataloging large amounts of transactional data. But the dawn of big data, with its associated technologies, and the recognition of data as a compass for decision making has paved the way for tools that can help enforce data governance.
Tools and frameworks such as Ataccama ONE , COLLIBRA , and Talend provide innovative ways of implementing data governance.
Monitoring and Threat Detection Along with technological advancements, we have seen a rise in new and dynamic cyber threats, transcending from threats like landline hacks and simple computer viruses to data exfiltration. Hackers have become more skilled at finding loopholes in data infrastructures and systems.
Fortunately, contemporary tools can add extra layers of security and quality assurance by monitoring some critical environments. They can also diagnose problems whenever they arise, and quickly notify analytics teams. A number of threat detection systems exist. XDR is a cloud-native detection and response tool that provides the ability to detect and respond to data security threats accordingly.Documentation Documentations are an integral part of data management best practices. Creating project documentation not only helps your colleagues follow through with the work done but educates them on the peculiarities of each dataset. Regardless of how true this is, developers spend long hours developing documentations.
But this can be better, as newer technologies like whatfix have improved the project documentation process through a series of easy-to-use interactive interfaces that guide developers on items to include in the project documentation.
In Conclusion
Legacy data management systems have different practices that are currently in use, though rigid, slow, and difficult to understand. But with the emergence of modern systems and frameworks, there is the ease of data management, ultimately ensuring reliable, agile, and flexible processes from collection till the data is used and archived.




